一、前言
如果你是一名 JavaScript 开发者,或者想要成为一名 JavaScript 开发者,那么你必须知道 JavaScript 程序内部的执行机制。执行上下文和执行栈是JavaScript中关键概念之一,是JavaScript难点之一。 理解执行上下文和执行栈同样有助于理解其他的 JavaScript 概念如提升机制、作用域和闭包等。本文尽可能用通俗易懂的方式来介绍这些概念。
我们先来看个例子:
1. 顺序执行?No
如果要问到 JavaScript 代码执行顺序的话,想必写过 JavaScript 的开发者都会有个直观的印象,那就是顺序执行,毕竟:
1 | var foo = function () { |
然而去看这段代码:
1 | function foo() { |
打印的结果却是两个 foo2。
刷过面试题的都知道这是因为 JavaScript 引擎并非一行一行地分析和执行程序,而是一段一段地分析执行。当执行一段代码的时候,会进行一个“准备工作”,比如第一个例子中的变量提升,和第二个例子中的函数提升。
但是本文真正想让大家思考的是:这个“一段一段”中的“段”究竟是怎么划分的呢?
到底JavaScript引擎遇到一段怎样的代码时才会做“准备工作”呢?
2. 可执行代码
这就要说到 JavaScript 的可执行代码(executable code)的类型有哪些了?
其实很简单,就三种:全局代码、函数代码、eval代码。
举个例子,当执行到一个函数的时候,就会进行准备工作,这里的“准备工作”,让我们用个更专业一点的说法,就叫做”执行上下文(execution context)”。
(JavaScript没有块级作用域,除了全局作用域之外,常用的只有函数可以创建作用域)
3. 执行上下文栈
接下来问题来了,我们写的函数多了去了,如何管理创建的那么多执行上下文呢?
所以 JavaScript 引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文
为了模拟执行上下文栈的行为,让我们定义执行上下文栈是一个数组:
1 | ECStack = []; |
试想当 JavaScript 开始要执行代码的时候,最先遇到的就是全局代码,所以初始化的时候首先就会向执行上下文栈压入一个全局执行上下文,我们用 globalContext 表示它,并且只有当整个应用程序结束的时候,ECStack 才会被清空,所以程序结束之前, ECStack 最底部永远有个 globalContext:
1 | ECStack = [ |
现在 JavaScript 遇到下面的这段代码了:
1 | function fun3() { |
当执行一个函数的时候,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出。知道了这样的工作原理,让我们来看看如何处理上面这段代码:
1 | // 伪代码 |
二、执行上下文(Execution Context)
1. 什么是执行上下文
简而言之,执行上下文就是当前 JavaScript 代码被解析和执行时所在环境的抽象概念, JavaScript 中运行任何的代码都是在执行上下文中运行。
2. 执行上下文的类型
执行上下文总共有三种类型:
- 全局执行上下文: 这是默认的、最基础的执行上下文。不在任何函数中的代码都位于全局执行上下文中。它做了两件事:1. 创建一个全局对象,在浏览器中这个全局对象就是 window 对象。2. 将 this 指针指向这个全局对象。一个程序中只能存在一个全局执行上下文。
- 函数执行上下文: 每次调用函数时,都会为该函数创建一个新的执行上下文。每个函数都拥有自己的执行上下文(严谨点讲,这个时候应该叫做作用域),但是只有在函数被调用的时候才会被创建。一个程序中可以存在任意数量的函数执行上下文。每当一个新的执行上下文被创建,它都会按照特定的顺序执行一系列步骤,具体过程将在本文后面讨论。
- Eval 函数执行上下文: 运行在 eval 函数中的代码也获得了自己的执行上下文,但由于 Javascript 开发人员不常用 eval 函数,所以在这里不再讨论。
三、执行上下文的生命周期
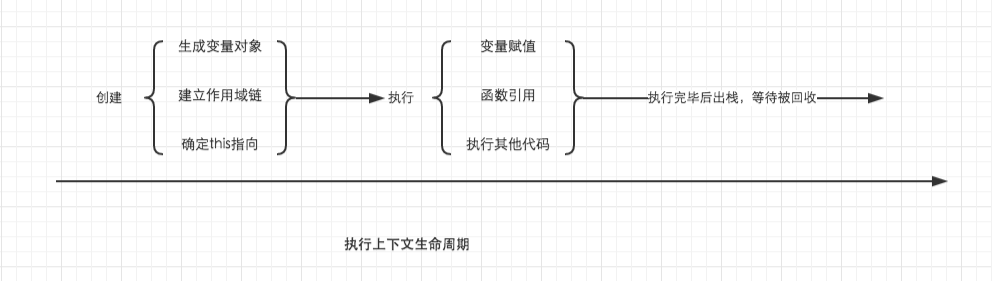
我们已经知道,当调用一个函数时(激活),一个新的执行上下文就会被创建。而一个执行上下文的生命周期可以分为两个阶段。
创建阶段
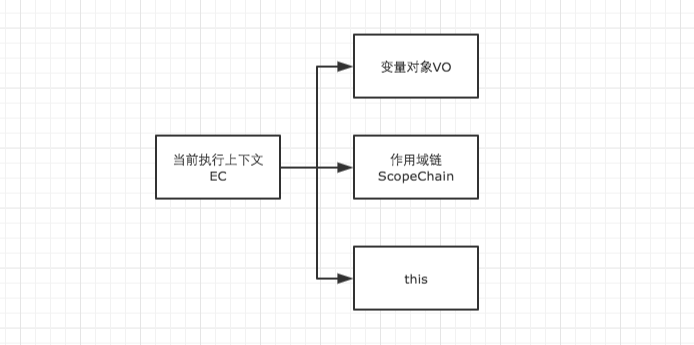
在这个阶段中,执行上下文会分别创建变量对象,建立作用域链,以及确定this的指向
代码执行阶段
创建完成之后,就会开始执行代码,这个时候,会完成变量赋值,函数引用,以及执行其他代码。
从这里我们就可以看出详细了解执行上下文极为重要,因为其中涉及到了变量对象,作用域链,this等很多人没有怎么弄明白,但是却极为重要的概念,因此它关系到我们能不能真正理解JavaScript。
执行上下文的生命周期包括三个阶段:创建阶段 → 执行阶段 → 回收阶段,本文重点介绍创建阶段。
1. 创建阶段
- 当函数被调用,但未执行任何其内部代码之前,会做以下三件事:
- 创建变量对象:首先初始化函数的参数arguments,提升函数声明和变量声明。下文会详细说明。
- 创建作用域链(Scope Chain):在执行期上下文的创建阶段,作用域链是在变量对象之后创建的。作用域链本身包含变量对象。作用域链用于解析变量。当被要求解析变量时,JavaScript 始终从代码嵌套的最内层开始,如果最内层没有找到变量,就会跳转到上一层父作用域中查找,直到找到该变量。
- 确定this指向:包括多种情况,下文会详细说明
在一段 JS 脚本执行之前,要先解析代码(所以说 JS 是解释执行的脚本语言),解析的时候会先创建一个全局执行上下文环境,先把代码中即将执行的变量、函数声明都拿出来。变量先暂时赋值为undefined,函数则先声明好可使用。这一步做完了,然后再开始正式执行程序。
另外,一个函数在执行之前,也会创建一个函数执行上下文环境,跟全局上下文差不多,不过 函数执行上下文中会多出this arguments和函数的参数。
2. 执行阶段
执行变量赋值、代码执行
3. 回收阶段
执行上下文出栈等待虚拟机回收执行上下文
四、变量对象
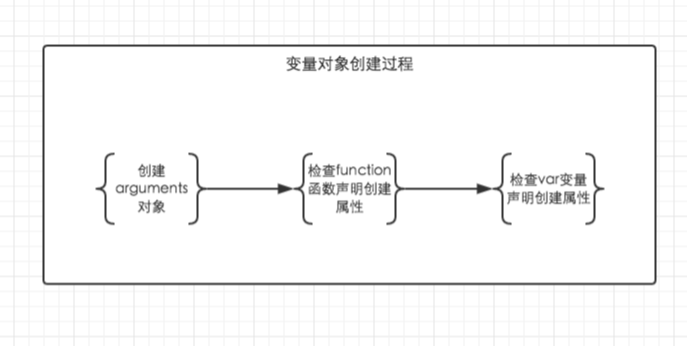
1. 变量对象的创建,依次经历了以下几个过程。
(1)建立arguments对象。检查当前上下文中的参数,建立该对象下的属性与属性值。
(2)检查当前上下文的函数声明,也就是使用function关键字声明的函数。在变量对象中以函数名建立一个属性,属性值为指向该函数所在内存地址的引用。如果函数名的属性已经存在,那么该属性将会被新的引用所覆盖。
(3)检查当前上下文中的变量声明,每找到一个变量声明,就在变量对象中以变量名建立一个属性,属性值为undefined。如果该变量名的属性已经存在,为了防止同名的函数被修改为undefined,则会直接跳过,原属性值不会被修改。
2. 举个例子
根据这个规则,理解变量提升就变得十分简单了。在很多文章中虽然提到了变量提升,但是具体是怎么回事还真的很多人都说不出来,以后在面试中用变量对象的创建过程跟面试官解释变量提升,保证瞬间提升逼格。
在上面的规则中我们看出,function声明会比var声明优先级更高一点。为了帮助大家更好的理解变量对象,我们结合一些简单的例子来进行探讨。
1 | // demo01 |
在上例中,我们直接从test()的执行上下文开始理解。全局作用域中运行test()时,test()的执行上下文开始创建。为了便于理解,我们用如下的形式来表示
1 | 创建过程 |
未进入执行阶段之前,变量对象中的属性都不能访问!但是进入执行阶段之后,变量对象转变为了活动对象,里面的属性都能被访问了,然后开始进行执行阶段的操作。
这样,如果再面试的时候被问到变量对象和活动对象有什么区别,就又可以自如的应答了,他们其实都是同一个对象,只是处于执行上下文的不同生命周期。
1 | // 执行阶段 |
因此,上面的例子demo1,执行顺序就变成了这样
1 | function test() { |
3. 全局上下文的变量对象
以浏览器中为例,全局对象为window。
全局上下文有一个特殊的地方,它的变量对象,就是window对象。而这个特殊,在this指向上也同样适用,this也是指向window。
1 | // 以浏览器中为例,全局对象为window |
除此之外,全局上下文的生命周期,与程序的生命周期一致,只要程序运行不结束,比如关掉浏览器窗口,全局上下文就会一直存在。其他所有的上下文环境,都能直接访问全局上下文的属性。
五、变量提升和this指向的细节
1. 变量声明提升
大部分编程语言都是先声明变量再使用,但在JS中,事情有些不一样:
1 | console.log(a)// undefined |
上述代码正常输出undefined而不是报错Uncaught ReferenceError: a is not defined,这是因为声明提升(hoisting),相当于如下代码:
1 | var a; //声明 默认值是undefined “准备工作” |
2. 函数声明提升
我们都知道,创建一个函数的方法有两种,一种是通过函数声明function foo(){} 另一种是通过函数表达式var foo = function(){} ,那这两种在函数提升有什么区别呢?
1 | console.log(f1) // function f1(){} |
接下来我们通过一个例子来说明这个问题:
1 | function test() { |
在上面的例子中,foo()调用的时候报错了,而bar能够正常调用。
我们前面说过变量和函数都会上升,遇到函数表达式 var foo = function(){}时,首先会将var foo上升到函数体顶部,然而此时的foo的值为undefined,所以执行foo()报错。
而对于函数bar(), 则是提升了整个函数,所以bar()才能够顺利执行。
有个细节必须注意:当遇到函数和变量同名且都会被提升的情况,函数声明优先级比较高,因此变量声明会被函数声明所覆盖,但是可以重新赋值。
1 | alert(a); // 输出:function a(){ alert('我是函数') } |
function声明的优先级比var声明高,也就意味着当两个同名变量同时被function和var声明时,function声明会覆盖var声明
这代码等效于:
1 | function a(){alert('我是函数')} |
最后我们看个复杂点的例子:
1 | function test(arg){ |
这是因为当函数执行的时候,首先会形成一个新的私有的作用域,然后依次按照如下的步骤执行:
- 如果有形参,先给形参赋值
- 进行私有作用域中的预解释,函数声明优先级比变量声明高,最后后者会被前者所覆盖,但是可以重新赋值
- 私有作用域中的代码从上到下执行
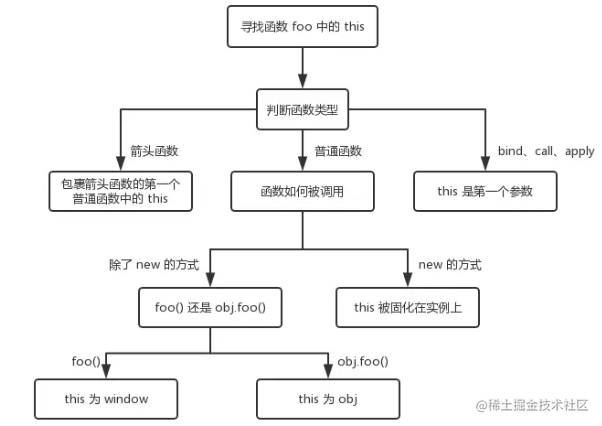
3. 确定this的指向
先搞明白一个很重要的概念 —— this的值是在执行的时候才能确认,定义的时候不能确认! 为什么呢 —— 因为this是执行上下文环境的一部分,而执行上下文需要在代码执行之前确定,而不是定义的时候。看如下例子:
1 | // 情况1 |
接下来我们逐一解释上面几种情况
- 对于直接调用 foo 来说,不管 foo 函数被放在了什么地方,this 一定是 window
- 对于 obj.foo() 来说,我们只需要记住,谁调用了函数,谁就是 this,所以在这个场景下 foo 函数中的 this 就是 obj 对象
- 在构造函数模式中,类中(函数体中)出现的this.xxx=xxx中的this是当前类的一个实例
- call、apply和bind:this 是第一个参数
- 箭头函数this指向:箭头函数没有自己的this,看其外层的是否有函数,如果有,外层函数的this就是内部箭头函数的this,如果没有,则this是window。
六、执行上下文栈(Execution Context Stack)
函数多了,就有多个函数执行上下文,每次调用函数创建一个新的执行上下文,那如何管理创建的那么多执行上下文呢?
JavaScript 引擎创建了执行上下文栈来管理执行上下文。可以把执行上下文栈认为是一个存储函数调用的栈结构,遵循先进后出的原则。

从上面的流程图,我们需要记住几个关键点:
- JavaScript执行在单线程上,所有的代码都是排队执行。
- 一开始浏览器执行全局的代码时,首先创建全局的执行上下文,压入执行栈的顶部。
- 每当进入一个函数的执行就会创建函数的执行上下文,并且把它压入执行栈的顶部。当前函数执行完成后,当前函数的执行上下文出栈,并等待垃圾回收。
- 浏览器的JS执行引擎总是访问栈顶的执行上下文。
- 全局上下文只有唯一的一个,它在浏览器关闭时出栈。
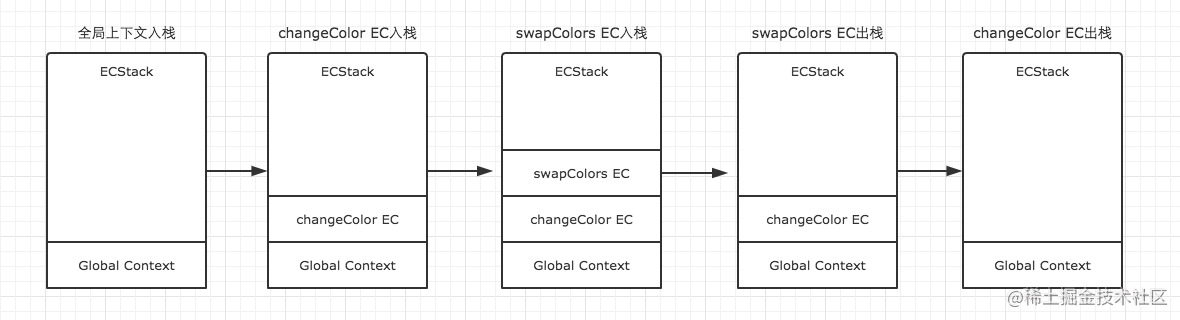
我们再来看个例子:
1 | var color = 'blue'; |
上述代码运行按照如下步骤:
- 当上述代码在浏览器中加载时,JavaScript 引擎会创建一个全局执行上下文并且将它推入当前的执行栈
- 调用 changeColor函数时,此时changeColor函数内部代码还未执行,js执行引擎立即创建一个changeColor的执行上下文(简称EC),然后把这执行上下文压入到执行栈(简称ECStack)中。
- 执行changeColor函数过程中,调用swapColors函数,同样地,swapColors函数执行之前也创建了一个swapColors的执行上下文,并压入到执行栈中。
- swapColors函数执行完成,swapColors函数的执行上下文出栈,并且被销毁。
- changeColor函数执行完成,changeColor函数的执行上下文出栈,并且被销毁。
七、作用域与执行上下文
许多开发人员经常混淆作用域和执行上下文的概念,误认为它们是相同的概念,但事实并非如此。
我们知道JavaScript属于解释型语言,JavaScript的执行分为:解释和执行两个阶段,这两个阶段所做的事并不一样:
解释阶段:
- 词法分析
- 语法分析
- 作用域规则确定
执行阶段:
- 创建执行上下文
- 执行函数代码
- 垃圾回收
JavaScript解释阶段便会确定作用域规则,因此作用域在函数定义时就已经确定了,而不是在函数调用时确定,但是执行上下文是函数执行之前创建的。执行上下文最明显的就是this的指向是执行时确定的。而作用域访问的变量是编写代码的结构确定的。
作用域和执行上下文之间最大的区别是: 执行上下文在运行时确定,随时可能改变;作用域在定义时就确定,并且不会改变。
一个作用域下可能包含若干个上下文环境。有可能从来没有过上下文环境(函数从来就没有被调用过);有可能有过,现在函数被调用完毕后,上下文环境被销毁了;有可能同时存在一个或多个(闭包)。同一个作用域下,不同的调用会产生不同的执行上下文环境,继而产生不同的变量的值。
八、总结
1. 调用一个函数时,一个新的执行上下文就会被创建:
创建执行上下文时会创建变量对象、建立作用域链、确定this指向等,然后压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出。执行上下文的生命周期为创建 - 执行 - 回收。
2. 执行上下文中的变量对象:
(1)变量对象是 arguments对象、变量对象中以函数名建立一个属性(value是函数的内存地址)、检查var变量,声明创建属性。
1 | VO = { |
(2)执行之后,变量对象称为执行对象。(未执行阶段,变量对象中的属性不能访问)
3. JS代码运行过程概述(以及变量环境和词法环境的区别):
(1)编译是把代码拿过来创建执行上下文,并创建变量环境、词法环境、可执行代码,将执行上下文压入执行栈。(这里说的编译是把解释(确定作用域等)和执行前的准备阶段(执行上下文)都包含了。)
(2)执行是在当前执行上下文环境下执行可执行代码。
(记住:解释是代码写好之后就做的,而执行前的准备阶段是必须调用代码后才做的)
变量环境:通过var声明或function(){}声明的变量存在这里
词法环境:通过let const with() try-catch创建的变量存在这里
可执行代码:变量声明提前后,剩下的代码
4. 编译原理
(1)JS编译执行概述
我们知道JavaScript属于解释型语言,JavaScript的执行分为:解释和执行两个阶段,这两个阶段所做的事并不一样:
解释阶段:
- 词法分析
- 语法分析
- 作用域规则确定
执行阶段:
- 创建执行上下文
- 执行函数代码
- 垃圾回收
JavaScript解释阶段便会确定作用域规则,因此作用域在函数定义时就已经确定了,而不是在函数调用时确定。但是执行上下文是函数执行之前创建的,执行上下文最明显的就是this的指向是执行时确定的。而作用域访问的变量是编写代码的结构确定的。
(2)编译原理
JavaScript 引擎进行编译的步骤和传统的编译语言非常相似,在传统的编译语言中,程序中的代码在执行之后会经历三个步骤:词法分析、语法分析、代码生成:
词法分析:这个阶段会将源代码拆成最小的、不可再分的词法单元(token)。比如代码 var name = ‘hello’;通常会被分解成 var 、name、=、hello、; 这五个词法单元。代码中的空格在 JavaScript 中是被直接忽略的。
语法分析:这个过程是将上一步生成的 token 数据,根据语法规则转为 AST。如果源码符合语法规则,这一步就会顺利完成。如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”。
可执行代码生成:这一步就是将AST转化为可执行代码,简单来说就是将 var name = ‘hello’; 的AST转化为一组机器指令,用来创建一个 name 变量(需要给name分配内存),并将一个值储存在 name 中。
比起那些编译过程只有三个步骤的语言的编译器,JavaScript 引擎要复杂的多,这里不再细说。总之,任何JavaScript代码片段在执行前都要进行编译,因此在 JS 引擎眼里,var name = ‘hello’; 语句包含了两个声明:
- var name (编译时处理)
- name = ‘hello’ (运行时处理)
你可能会问,JS 不是不存在编译阶段的“动态语言”吗?事实上,JS 也是有编译阶段的,它和传统语言的区别在于,JS 不会早早地把编译工作做完,而是一边编译一边执行。简单来说,所有的 JS 代码片段在执行之前都会被编译,只是这个编译的过程非常短暂(可能就只有几微妙、或者更短的时间),紧接着这段代码就会被执行。
在编译阶段和执行阶段阶段的过程如下:
- 编译阶段: 编译器会找遍当前作用域,看看是不是已经有一个叫 name 的变量。如果有,那么就忽略 var name 这个声明,继续编译下去;如果没有,则在当前作用域里新增一个 name。然后,编译器会为引擎生成运行时所需要的代码,程序就进入了执行阶段。
- 执行阶段: JS 引擎在执行代码的时候,仍然会查找当前作用域,看看是不是有一个叫 name 的变量。如果能找到,就给它赋值。如果找不到,就会从当前作用域里向上层作用域逐级查找。如果最终仍然找不到 name 变量,引擎就会抛出一个异常。
这里,JS引擎的查找过程就是作用域链,作用域指的是变量能够被访问到的范围。